Data cleaning is a critical step in the data preprocessing pipeline that involves the identification and resolution of errors and inconsistencies in your dataset. The significance of this process is aptly captured by the saying, “Garbage In, Garbage Out.” In other words, the quality of the input data influences the quality of the results obtained from any data analysis or modeling efforts. In this article, we will explore various data cleaning techniques that can be applied holistically for both continuous and discrete data with clear concept explanation, example code, Pros and Cons of using the method, which will help you better understand the problem at hand

First lets define Numerical columns and types of data in numerical columns
Numerical Variables are a fundamental aspect of data, representing quantitative measurements or quantities. They are classified into two primary types based on their characteristics:
- Discrete variables have a finite or countable number of possible values.
- Examples: Number of Children, Number of Cars, Number of Students in a Class.
- Continuous variables can take on any value within a certain range.
- Examples: Height, Weight, Age, Income.
Certainly! While there isn’t a one-size-fits-all way to clean data because every dataset, goal, and tool is different, there are basic steps you can follow to clean up your data. Here’s a simplified guide for cleaning data:
The Dataset
Imagine we have a dataset containing information about customer orders in an e-commerce platform. The dataset includes various numerical columns, such as order quantities, prices, and delivery times.
# Import the necessary libraries
import pandas as pd
# Load the dataset
df = pd.read_csv('ecommerce_orders.csv')
1. Handling missing data in data cleaning
Handling missing data is a crucial aspect of data cleaning and preparation, as missing values can adversely affect the quality and reliability of your dataset. There are various techniques to address missing data, depending on the nature of the data and the context of your analysis. Here, we will discuss common approaches to handle missing data:
1.1 Deletion of Missing Data
In this approach, you simply remove records (rows) or features (columns) that contain missing values. There are two common subtypes of deletion:
- Listwise Deletion: Also known as “complete case analysis,” this method involves removing entire rows with any missing values.
- Column Deletion: You remove entire columns (features) that have a substantial number of missing values.
Pros:
- Simple and straightforward.
- Works well when missing data is completely at random (MCAR).
Cons:
- Can result in a significant loss of information, especially if many rows or important features have missing values.
- Not suitable when the missingness is related to the outcome (e.g., missing salary data for low-income individuals).
Python Code:
# Remove rows with missing values
df_cleaned = df.dropna()
# Remove columns with missing values (e.g., columns with more than 10% missing)
threshold = 0.1 # Adjust the threshold as needed
df_cleaned = df.dropna(axis=1, thresh=len(df) * (1 - threshold))
1.2 Imputation:
Imputation involves filling in missing values with estimated or calculated values based on the available data. There are several imputation techniques:
- Mean/Median Imputation: Replace missing values with the mean or median of the column.
- Mode Imputation: Replace missing values with the mode (most frequent value) of the column for ordinal data.
- Regression Imputation: Predict missing values using regression models based on other variables.
- K-Nearest Neighbors (K-NN) Imputation: Impute missing values based on the values of the nearest neighbors in the dataset.
Pros:
- Retains all data points, minimizing information loss.
- Suitable for various types of missing data mechanisms.
Cons:
- May introduce bias if data is not missing completely at random (MAR).
- Assumes relationships between variables are linear (for regression imputation).
Python Code:
# Impute missing values with the mean of the column
df['column_name'].fillna(df['column_name'].mean(), inplace=True)
# Impute missing values with the mode of the column
df['categorical_column'].fillna(df['categorical_column'].mode()[0], inplace=True)
# Regression Imputation
from sklearn.linear_model import LinearRegression
model = LinearRegression().fit(df_not_missing[['predictor1', 'predictor2']], df_not_missing['target_column'])
df.loc[df['target_column'].isnull(), 'target_column'] = model.predict(df_missing[['predictor1', 'predictor2']])
# KNN Imputer
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5) # You can adjust the number of neighbors as needed
df[columns_to_impute] = imputer.fit_transform(df[columns_to_impute])
1.3 Interpolation
Interpolation is a technique commonly used for time series or sequential data. It estimates missing values based on the values of adjacent time points or observations. Common methods include linear interpolation, polynomial interpolation, and spline interpolation.
Given two adjacent data points (x₁, y₁) and (x₂, y₂), linear interpolation estimates values at positions between them by connecting them with a straight line. The interpolated value (y) at a point x within the range [x₁, x₂] can be calculated as:
Formula: y = y₁ + (x - x₁) * [(y₂ - y₁) / (x₂ - x₁)]
Python Code:
# Perform linear interpolation for missing values in a time series
df['column_name'].interpolate(method='linear', inplace=True)
Pros:
- Retains the time-based or sequential nature of the data.
- Suitable for time series data with missing values.
Cons:
- May not work well for non-sequential data.
- Requires a sufficient amount of adjacent data points for accurate interpolation.
2. Outlier detection and Treatment
2.1 Outlier Detection Using Z-Score and IQR(Inter- Quartile Range)
Z-score
The Z-score measures how many standard deviations a data point is away from the mean. Data points with Z-scores beyond a certain threshold (often 2 or 3 standard deviations) are considered outliers. Here are various ways to handle outliers once they are detected:
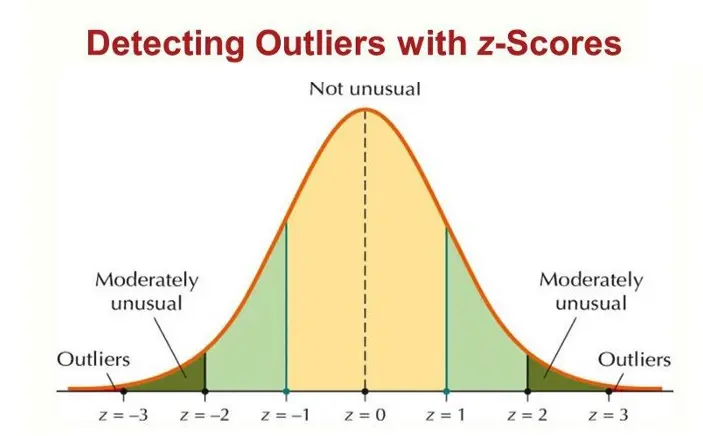
Python Code:
import numpy as np
from scipy import stats
# Sample dataset (replace this with your data)
data = np.array([12, 15, 14, 18, 20, 21, 25, 30, 45, 200])
# Calculate Z-scores for each data point
z_scores = np.abs(stats.zscore(data))
# Define a Z-score threshold (e.g., 2 for a 95% confidence level)
threshold = 2
# Identify outliers based on the Z-score threshold
outliers = np.where(z_scores > threshold)
IQR(Interquartile Range)
The Interquartile Range (IQR) is a statistical measure used to assess the spread or dispersion of a dataset, particularly in the context of its middle 50%. It’s a valuable tool for identifying and understanding the variability of data. The IQR is defined as the range between the first quartile (Q1) and the third quartile (Q3) of a dataset, representing the range within which the central 50% of the data falls.
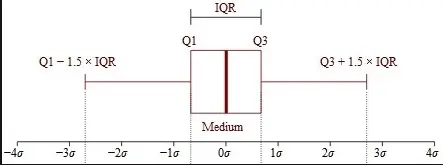
Python Code:
import numpy as np
# Sample dataset (replace this with your data)
data = np.array([12, 15, 14, 18, 20, 21, 25, 30, 45, 200])
# Calculate the first quartile (Q1) and third quartile (Q3)
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
# Calculate the interquartile range (IQR)
iqr = q3 - q1
# Define the lower and upper bounds for outliers
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
# Identify outliers based on the IQR bounds
outliers = np.where((data < lower_bound) | (data > upper_bound))
# Print the identified outliers
print("Outliers:", data[outliers])
2.2 Removing Outliers:
Removing outliers involves eliminating entire rows that contain outlier values. This is a straightforward approach, but it can result in a significant loss of data.
Pros:
- Improved Data Quality: Removing outliers enhances data quality by eliminating extreme values that can introduce noise and distort statistical analysis.
- Enhanced Model Performance: Eliminating outliers can lead to more accurate and robust statistical models, as these extreme values may disproportionately affect model parameters.
Cons:
- Loss of Information: Removing outliers may result in the loss of valuable data points that could contain meaningful insights or rare events.
- Subjectivity: Deciding which data points to remove as outliers can be subjective and
Python Code:
# Define the column containing data with potential outliers
column_with_outliers = 'column_name'
# Calculate Z-scores for the column
z_scores = np.abs((df[column_with_outliers] - df[column_with_outliers].mean()) / df[column_with_outliers].std())
# Set the Z-score threshold for outlier removal (e.g., 3 standard deviations)
z_score_threshold = 3
# Remove outliers
df_no_outliers = df[z_scores <= z_score_threshold]
2.2 Removing Outliers:
In this approach, you cap or extend outlier values to a certain threshold, which helps prevent extreme values from having a disproportionate impact on your analysis.
Pros:
- Preserves Data Volume: Unlike complete removal, capping or extending outliers allows you to retain all data points, preserving the original data volume.
- Mitigates Impact: By limiting the effect of outliers to a specified threshold, this method reduces the potential for extreme values to skew your analysis significantly.
Cons:
- Data Transformation: Capping or extending outliers involves altering the original data, which can lead to a distortion of the data distribution.
- Loss of Extreme Information: By modifying extreme values to fit within a threshold, you may lose information about the true nature of extreme observations.
Python Code:
# Define the column containing data with potential outliers
column_with_outliers = 'column_name'
# Calculate Z-scores for the column
z_scores = np.abs((df[column_with_outliers] - df[column_with_outliers].mean()) / df[column_with_outliers].std())
# Set the Z-score threshold for capping outliers (e.g., 3 standard deviations)
z_score_threshold = 3
# Define the threshold value for capping outliers
threshold_value = 3 * df[column_with_outliers].std() # Adjust the threshold as needed
# Cap outliers to the threshold value
df[column_with_outliers] = np.where(z_scores > z_score_threshold, threshold_value, df[column_with_outliers])
2.3 Transforming Outliers:
Transforming outliers can be an effective way to make the data more suitable for analysis. One common transformation is the log transformation.
The log transformation involves taking the natural logarithm (base e) of each data point in a given variable. Mathematically, the log transformation of a data point x is represented as: ln(x)
Where: ln represents the natural logarithm function. x is the original data point.
Ex: Consider Original data as {1, 10, 100, 1000} lets see how the data transforms after applying log to it
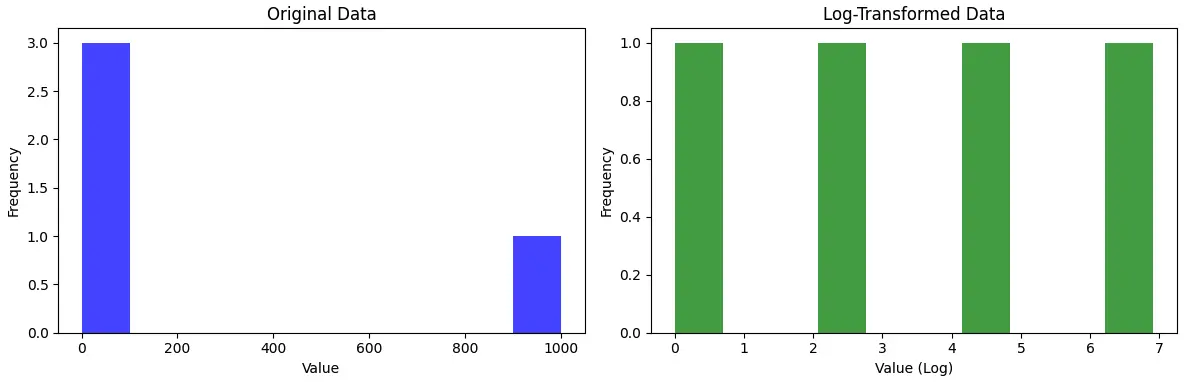
Python code:
# Sample data
data = {'Value': [1, 10, 100, 1000]}
df = pd.DataFrame(data)
# Define the column name
column_name = 'Value'
# Log-transform the specified column
df[column_name + '_log'] = np.log(df[column_name])
Pros:
- Normalization: Log transformation can help normalize the data by reducing the impact of extreme values or outliers, making it suitable for statistical methods that assume normality.
- Symmetry: It can make right-skewed (positively skewed) data distributions more symmetric, making it easier to apply statistical techniques that assume symmetric data.
- Stabilization of Variance: In some cases, log transformation can stabilize the variance across different levels of the independent variable, which is beneficial for linear regression and other modeling techniques.
- Interpretability: In cases where the relationship between variables is multiplicative, log-transformed data can be interpretable
Cons:
- Data Interpretation: Log-transformed data may be less intuitive to interpret because it operates on a different scale. Changes in the log-transformed data do not directly correspond to changes in the original data.
- Inapplicability to Zero or Negative Values: Log transformation is not defined for zero or negative values. In such cases, you may need to add a constant to the data before transformation.
- Limited Usefulness for Already-Normal Data: Log transformation may not provide significant benefits for data that is already normally distributed or nearly so. Applying a log transformation unnecessarily to such data can introduce complexity without substantial gain.
- Loss of Information: While log transformation can mitigate the impact of outliers, it may also result in a loss of information about the original extreme values. The transformed data may not accurately represent the true magnitude of those values.
- Model Interpretation: Interpreting coefficients in a model involving log-transformed variables can be less straightforward, as the coefficients relate to changes in log values, not the original scale.
3. Scaling
Scaling is about making sure all the numbers in your data play nicely together. It helps in comparing and understanding data better. Scaling also deals with outliers and makes things work better in computer models. It’s like getting all your data on the same page for a smoother analysis.
Think of scaling like adjusting the volume on a music player. It ensures that all the songs play at the same volume level, so you can enjoy your music without one song being too loud or too soft. Similarly, scaling in data helps ensure that different data points “sound” consistent and harmonious for analysis or modeling
3.1 Min-Max Scaling (Normalization):
Commonly used when you want to transform data to a consistent range that preserves the original data distribution. It’s widely used in machine learning and data preprocessing.
Method: Scales data to a specific range, typically [0, 1].
Formula: Min-Max Scaling(x)= $\frac{x−min(X)}{max(X)−min(X)}$
Python code:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# Sample data
data = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]])
# Create a MinMaxScaler instance
scaler = MinMaxScaler()
# Fit the scaler to your data and transform it
scaled_data = scaler.fit_transform(data)
# Print the scaled data
print(scaled_data)
#Output : [[0.0][0.25][0.5 ][0.75][1.0]]
Pros:
- Normalization: Min-Max scaling transforms data into a specific range, typically [0, 1]. This normalization makes it easier to compare and analyze data across different scales and units.
- Preservation of Data Distribution: Min-Max scaling preserves the original data distribution and does not change the shape of the data’s probability distribution. This is valuable when you want to maintain the integrity of the original data distribution.
Cons:
- Sensitivity to Outliers: Min-Max scaling can be sensitive to outliers. If your dataset contains extreme values, the scaling process may compress the majority of the data points into a narrow range, making the distribution less representative of the data.
- Impact on Sparse Data: In cases where your data is sparse (i.e., mostly composed of zeros or missing values), Min-Max scaling can exaggerate the importance of non-zero values, potentially affecting the performance of certain algorithms.
3.2 Z-Score Scaling (Standardization):
Frequently used when dealing with data that follows or approximates a normal distribution. It’s valuable for statistical analysis and modeling, especially when comparing variables with different units.
Method: Standardizes data to have a mean(μ) of 0 and a standard deviation(σ) of 1.
Formula: Z-Score Scaling(x)= $ \frac {x−μ}{σ}$
Python code :
from sklearn.preprocessing import StandardScaler
import numpy as np
# Sample data
data = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]])
# Create a StandardScaler instance
scaler = StandardScaler()
# Fit the scaler to your data and transform it
scaled_data = scaler.fit_transform(data)
# Print the scaled data
print(scaled_data)
# Output: [[-1.41421356][-0.70710678][ 0.0][ 0.70710678][ 1.41421356]
Pros:
- Mean Centering: Z-score scaling centers the data by subtracting the mean, resulting in a mean of 0. This helps eliminate any bias in the data.
- Standard Deviation: It scales the data to have a standard deviation of 1, which makes it easy to compare and interpret the relative spread of data.
- Outlier Handling: Z-score scaling is less sensitive to outliers compared to Min-Max scaling. It reduces the impact of extreme values on the scaled data.
Cons:
- Distribution Change: It can transform the data distribution, especially if the original data is not approximately normally distributed. This can impact the interpretability of data.
- Negative Values: Z-score scaling can result in negative scaled values, which may not be meaningful for some applications or algorithms.
3.3 Robust Scaling (Standardization):
Widely employed when dealing with data that contains outliers or when you want to minimize the influence of extreme values. It’s essential for robust statistical analysis and modeling. Unlike the mean, which is sensitive to outliers, the median is a robust measure of central tendency. It represents the middle value of the data and is not affected by extreme values.
Method: Scales data using the median and interquartile range (IQR), making it robust to outliers.
Formula: Robust Scaling(x)= $\frac{x−Median}{IQR}$
Python code :
import numpy as np
from sklearn.preprocessing import RobustScaler
# Sample data with outliers
data = np.array([[1.0], [2.0], [3.0], [4.0], [100.0]])
# Create a RobustScaler instance
scaler = RobustScaler()
# Fit the scaler to your data and transform it
scaled_data = scaler.fit_transform(data)
# Print the scaled data
print(scaled_data)
#Output
[[-1.0][-0.5][ 0.0][ 0.5][48.5]]
NOTE: Robust scaling doesnt completly eliminate the outliers, it just reduces the impact of the outliers. Extreme outliers after scaled can also be still apparent
Pros:
- Robust to Outliers: Robust scaling effectively handles outliers in the data. It uses the median and IQR, which are less influenced by extreme values, making it suitable for datasets with outliers.
- Preservation of Data Distribution: Unlike some other scaling methods, robust scaling preserves the original data distribution as much as possible. This is valuable when maintaining the integrity of the data distribution is important.
Cons:
- Limited Range: Robust scaling scales data based on the median and IQR, typically resulting in scaled values within a limited range. This may not be suitable for datasets with specific scaling requirements.
- Interpretability: The scaled values may not be as intuitive to interpret as those obtained through other scaling methods like Min-Max scaling or Z-score scaling.
4. Binning / Discretization:
Binning or discretization is a data preprocessing technique used to transform continuous numerical data into discrete intervals or bins. It can be helpful when you want to simplify complex numerical data or when certain algorithms require categorical or ordinal data. Binning involves dividing the range of continuous values into intervals and assigning data points to these intervals based on their values.
Method: Divide the data range into predefined bins or intervals and assign data points to these bins.
Python Code:
import pandas as pd
# Sample data
data = pd.DataFrame({'Age': [25, 30, 35, 40, 45, 50]})
# Define bin edges
bin_edges = [0, 30, 40, 100]
# Create labels for bins
bin_labels = ['Young', 'Middle-aged', 'Senior']
# Apply binning
data['Age Group'] = pd.cut(data['Age'], bins=bin_edges, labels=bin_labels)
Pros:
- Simplification: Binning simplifies complex numerical data by grouping values into discrete categories or intervals, making it easier to interpret and analyze.
- Categorical Data: Some machine learning algorithms require categorical or ordinal data as input. Binning allows you to convert continuous data into a format suitable for these algorithms.
Cons:
- Information Loss: Binning may result in information loss, as it reduces the granularity of the data. Fine details within each bin may be lost, impacting the accuracy of certain analyses.
- Choice of Bin Width: Selecting appropriate bin sizes or widths can be subjective and may affect the outcomes of the analysis. Poorly chosen bins can lead to misinterpretation.
- Outliers Handling: Binning does not inherently handle outliers well. Outliers may fall into extreme bins, and their impact may still affect the analysis within those bins.
- Impact on Model Performance: In some cases, binning can introduce noise or bias into models. It’s essential to carefully evaluate whether binning is appropriate for a particular analysis.
I hope I covered most common techniques used for cleaning numerical data. Clearly these just the common ones which I had to deal with while doing my projects. If your results aren’t looking right, double-check how you cleaned your data. And it’s really important to document everything you do to your data.
References:
[1] Shmueli, G., Bruce, P. C., Gedeck, P., & Patel, N. R. (2023). Data mining for business analytics: Concepts, techniques and applications in Python (3rd ed.). Wiley.