Loss functions in Classification
In the previous post, We have seen how the Loss/cost function works in regression and when to use which cost function. let us also see how that works for classification settings. Let’s dive in!
Graduate Level
- Binary Cross Entropy Loss function:
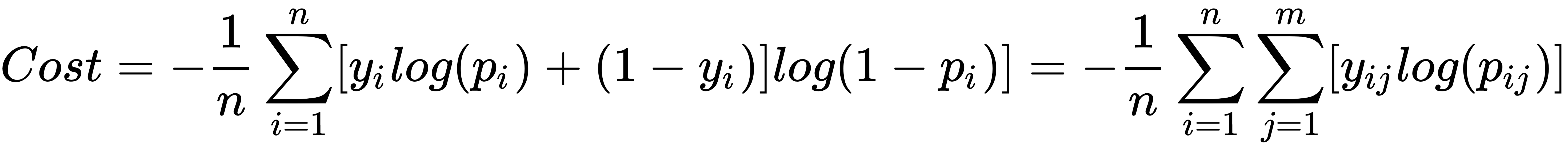 Image credits stackexchange
Image credits stackexchange
That’s a lot in the equation. to break it down, firstly we see why there is log loss in the equation. we know that log is a monotonically increasing function in total, so using log doesn’t affect distribution but there will be a change in scale. As we are finding log of probabilities, when the prob increases to reach 1, the log(1) reaches zero i.e loss is zero, this makes sense doesn’t it?
An Increase in prob decreases loss and a decrease in prob increases loss. (huh…ah moment)
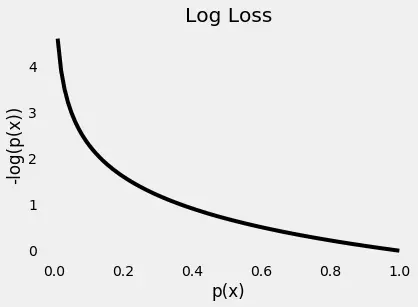 Image credits ml-cheatsheet
Image credits ml-cheatsheet
The plot above gives us a clear picture —as the predicted probability of the true class gets closer to zero, the loss increases exponentially.
In the above equation Yi refers to a class, let’s say 0,1 as class labels, class 0 makes the first term ‘0’ and class 1 makes the second term ‘0’, basically you are computing loss value with different probs having different classes.
- Hinge Loss:
The Hinge loss function is mainly used in Support Vector Machine settings. It is meant to be used with binary classification where target values are within the set.
 Image credits towardsdatascience
Image credits towardsdatascience
Let’s break down how the loss function works for SVM with the above representation:
- If the distance from the boundary is 0 (meaning that the datapoint is on the boundary), then we incur a loss size of 1.
- A negative distance from the boundary gives a high hinge loss. which says that we are on the wrong side of the boundary i.e misclassification.
- A positive distance from the boundary gives a low hinge loss, or zero hinge loss, and the further we are away from the boundary the lower our hinge loss will be. (when correctly classified)
You have seen what hinge loss is and how it works. Now, let’s see the mathematical formulation of hinge loss.
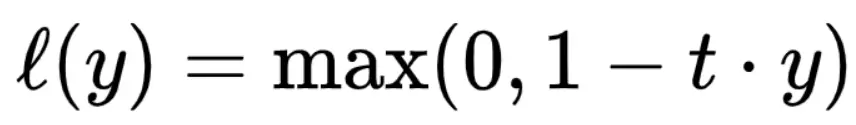 Image credits towardsdatascience
Image credits towardsdatascience
Note that y should be the “raw” output of the classifier’s decision function, not the predicted class label. For instance, in linear SVMs, y = w.x + b.
If the training data can be separated by a linear boundary, then any boundary which does so will have a hinge loss of zero— the lowest achievable value.
Only if the training data is not linearly separable will the best boundary have a nonzero (positive, worse) hinge loss. In that case, the hinge loss preference will prefer to choose the boundary so that whichever misclassified points are not too far on the wrong side.
Post Graduate Level
- KL Divergence: Kullback–Leibler
let me start with the concept of information. Information is defined as
I = - log( p(x) )
We know that probability is between 0 and 1 and for the values, less than 1 the log is -ve,
- If prob is very small, - log of a very small number is large
- If prob is large, - log is very small,
You should have got the intuition by now, The greater the prob the less information you get. The less the prob the more information you get.
let’s say an event you know will occur at high prob, there is no additional information you gain because you already know the event is going to happen if someone says the asteroid is going to hit in the next 5 secs. In this case, you gained much information from an unlikely event, for which prob is less.
Another concept relevant to Information is the ‘average of information’ - entropy: expectation of information.
H = - sum( p(x)*log(p(x)) )
Now relating all together **KL-divergence is a measure of dissimilarity of two distributions.** KL(p||q) = lets put it this way entropy(p) - entropy(q) {average info from p dsitribution - average info of q distribution} But if you see KL(p||q) is one distribution with respect to other so that changes to
KL(p||q) = - sum( p(x)*log(q(x)) ) + sum( p(x)*log(p(x)) )
i.e (avg info of q with respect to p - avg info of p)
There are two important things in KL-Divergence:
- It is always greater than zero
- It is not symmetric i.e KL(q||p) ≠ KL(p||q)
Uses:
- Let's say you are using autoencoders and you don't want your decoder to mimic the input, thus KLD is used as a loss metric to find out how the decoded sequence diverges from the input sequence.
- It's specifically used to measure how different two distributions are.
But, what about the loss functions in place that are used in high-level settings such as Generative Adversarial Networks like:
- minimax loss
- Wasserstein loss
Well, that's a post for another what-if!
You kind of took a mini post-graduate degree in loss functions! KUDOS
-Siddhartha Putti
putti.s@northeastern.edu