PAC learning is a framework for mathematical analysis of machine learning, that aims to select a hypothesis that has a low error, with high probability.
PAC model has two parameters -> \(\epsilon\) and \(\delta\). It requires that with a probability of at least \(1-\delta\), the model learns a concept with an error of at most \(\epsilon\) i.e., with an accuracy of \(1-\epsilon\). \(\delta\) gives the failure to achieve the accuracy of \(1-\epsilon\) i.e., \(1-\delta\) gives the confidence of achieving the accuracy of \(1-\epsilon\).
Example: Learn the concept “University Acceptance”
Suppose we are given the undergraduate GPA and GRE score of n students that previously applied to this university (the training set). Each student is labeled as accepted or not accepted.
The task is to build a supervised learning model that correctly predicts if a pair [Undergraduate GPA, GRE score] will be accepted to the university or not.
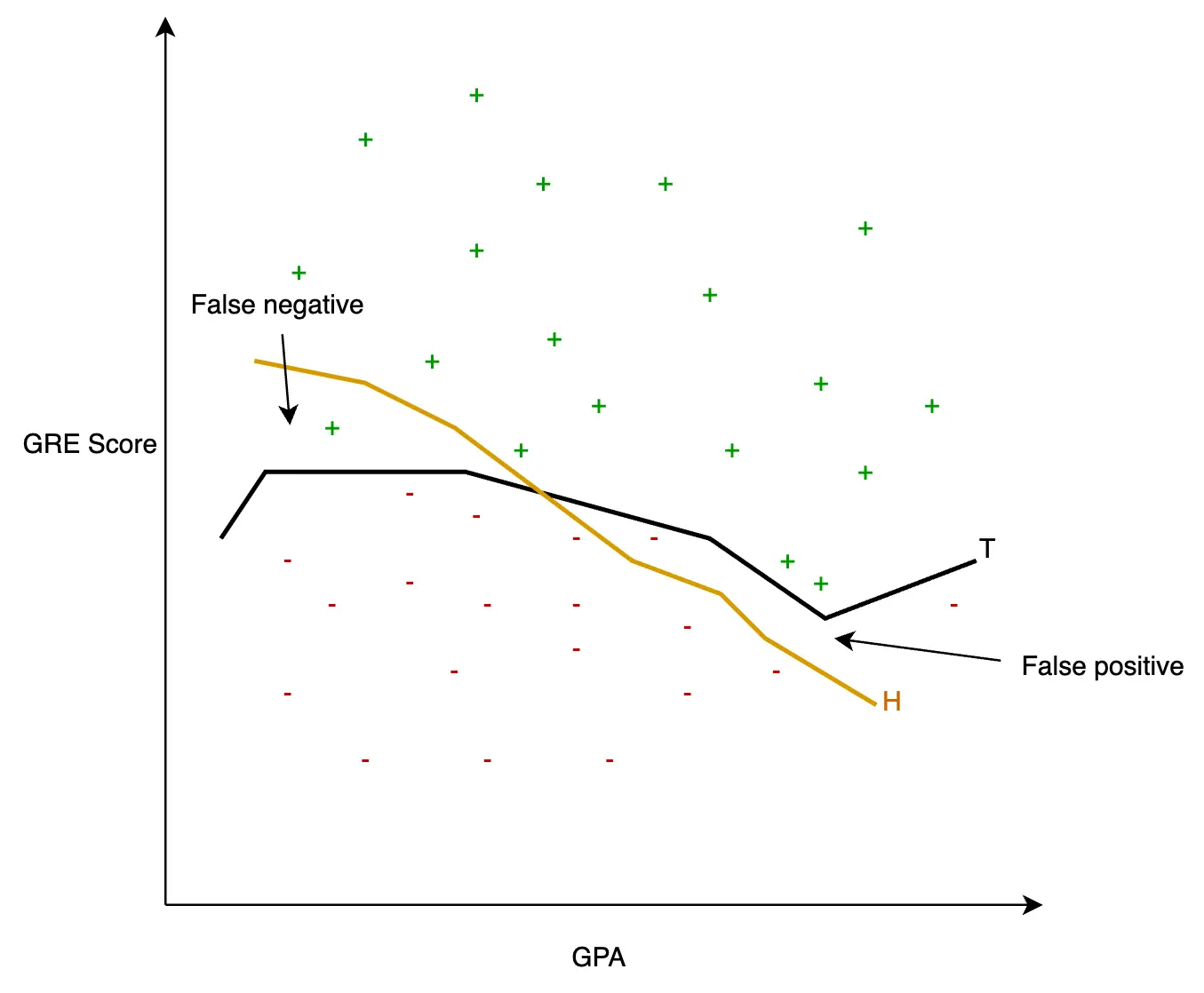
Figure. True trend (T) and derived hypothesis (H) of university acceptance
This figure presents the GPAs and the GRE scores on the x-axis and y-axis respectively. T represents the true trend line, while H represents the hypothesis formulated to closely represent the true trend. The hypothesis misclassifies true positive records that fall in the false negative region as reject and true negative records that fall in the false positive region as accept.
Error region = \(T \textrm{ XOR } H\)
We want this error region to be less than or equal to \(\epsilon\) with a probability of at least \(1-\delta\).
Approximately correct
A hypothesis is said to be approximately correct, if the probability of error is less than or equal to \(\epsilon\), where \(0\le\epsilon\le1/2\)
That is, \(P(T \oplus H) \le \epsilon\)
Probably approximately correct
As the training samples are drawn randomly, there is a chance for the selected training sample to be misleading. Hence, these training samples are not always actual representations of the population, in which case the hypothesis generated may not be approximately correct.
Therefore, the goal is to achieve low generalization error with high probability.
\[P(Error(H) \le \epsilon) > 1-\delta\] \[P(P(T \oplus H) \le \epsilon) > 1-\delta\]Now, suppose we have been given the below errors of a hypothesis: H1 on 5 different sample sets of the university acceptance training set. \(\epsilon\) =0.05, \(\delta\)=0.2.
| Sample set | Error(H1) |
|---|---|
| 1 | 0.069 |
| 2 | 0.03 |
| 3 | 0.021 |
| 4 | 0.05 |
| 5 | 0.013 |
Out of the 5 sample sets, the error on the sample set 1 is greater than the upper bound of the error; 0.05. Therefore, the hypothesis is incorrect for the sample set 1. Hence, we can say that the hypothesis is approximately correct 4/5 (0.8) times. Since 0.8 \(\ge\) 1-0.2, we say that H1 is probably approximately correct.
Similarly, suppose below are the errors of another hypothesis: H2 on 5 different sample sets. \(\epsilon\)=0.05, \(\delta\)=0.2.
| Sample set | Error(H1) |
|---|---|
| 1 | 0.057 |
| 2 | 0.041 |
| 3 | 0.072 |
| 4 | 0.023 |
| 5 | 0.064 |
Out of the 5 sample sets, the errors on sample sets 1, 3, and 5 are greater than the upper bound of the error; 0.05. Therefore, the hypothesis is incorrect for sample sets 1, 3, and 5. Hence, we can say that the hypothesis is approximately correct 2/5 (0.4) times.
Since 0.4 \(<\) 1-0.2, we say that H2 is not probably approximately correct.
PAC learning in a generalized setting
Let \(X\) be all available instances over which a set of target concepts \(C\) should be learnt, where \(c \in C\) and \(c:X \rightarrow\{0,1\}\) (if \(x\) is positive, \(c(x)=1\) and if \(x\) is negative, \(c(x)=0\)).
Samples are drawn at random from \(X\) according to a probability distribution \(D\).
A learner \(L\) observes a set of training samples, and considers a set of hypothesis \(H\), out of which a certain \(h \in H\) is selected as an estimate for \(c\). The true error of the hypothesis \(h: error_D(h)\) is the probability of \(h\) misclassifying an instance drawn randomly according to \(D\).
\[error_D(h) = Pr_{h\in D}[c(x) \neq h(x)]\]Formal definition
Let \(C\) be a class of boolean functions \(f: \{0,1\}^n \rightarrow\{0,1\}\). We say that \(C\) is PAC-learnable if there exists an algorithm \(L\) such that for every \(f \in C\), for any probability distribution \(D\), for any \(\epsilon\) where \(0\le\epsilon\le1/2\), for any \(\delta\) where \(0\le\epsilon\le1\), algorithm \(L\) on input \(\epsilon\) and \(\delta\) and a set of random samples picked from any probability distribution \(D\) outputs at least with a probability 1-\(\delta\), concept \(h\) such that \(error(h,f) \le\epsilon\).