Team:
| Name | |
|---|---|
| Aartee Simran Dhomeja | dhomeja.a@northeastern.edu |
| Palakshi Choksi | choksi.pa@northeastern.edu |
| Yash Nema | nema.y@northeastern.edu |
| Zichen Fan | fan.zic@northeastern.edu |
Outline
- Introduction
- Data Source
- Work Flow
- Exploratory Data Analysis
- Data Cleaning
- Feature Engineering
- Statistical Learning Algorithm
- Results and Comparison
- Bias and Variance Trade-off
- Summary
1. Introduction
1.1. Problem Statement:
In today’s world, understanding the factors that influence income can help us find ways to improve economic opportunities and reduce income inequality. In this project, we will analyze the Adult Income dataset to predict whether an individual earns over $50,000 per year, based on their demographic and employment information.
1.2. Goal and Methodology:
To achieve this classification task, we have applied six different machine learning algorithms - Naive Bayes, Logistic Regression, Support Vector Machine, KNN, tree-based models, and Neural Network. There is no free lunch, we must balance each model’s strengths and weaknesses to achieve the best result. Therefore, we compare these models’ performances and select the best model for this specific problem.
Our dataset has various features such as age, education level, occupation, marital status, and more, which can all be used to predict an individual’s income level. By training our models on the data and evaluating their Precision, Recall, and F1-score, we can decide which algorithm performs the best on this task and gain insights into the key factors that influence income.
2. Data Source
Adult Income is the U.S. Census data from 1994. This dataset contains over 48,000 instances and 14 attributes, which include 9 categorical and 5 numerical attributes.
2.1. Feature Description
| Feature Name | Data Type | Description of Variable | Percentage of Missing Values |
|---|---|---|---|
| Age | Numeric | The Age of an individual | - |
| WorkClass | String | Simplified employment status of an individual | 5.73% |
| fnlgwt | Numeric | Final weight of the record (Interpreted as the number of people sharing similar attributes) |
- |
| Education | String | The Education level | - |
| Education Num | Numeric | The Education level is ascending positive integer value | - |
| Martial Status | String | Martial status of a person | - |
| Occupation | String | Category of the occupation | 5.75% |
| Relationship | String | Relationship in terms of family | - |
| Race | String | Race of the person | - |
| Sex | String | Gender at birth | - |
| Capital Gain | Numeric | Dollar gain of capital | - |
| Capital loss | Numeric | Dollar loss of capital | - |
| Hours per week | Numeric | Working hours per week | - |
| Native country | String | Country at birth | 1.75% |
2.2. Data Overview

3. Workflow
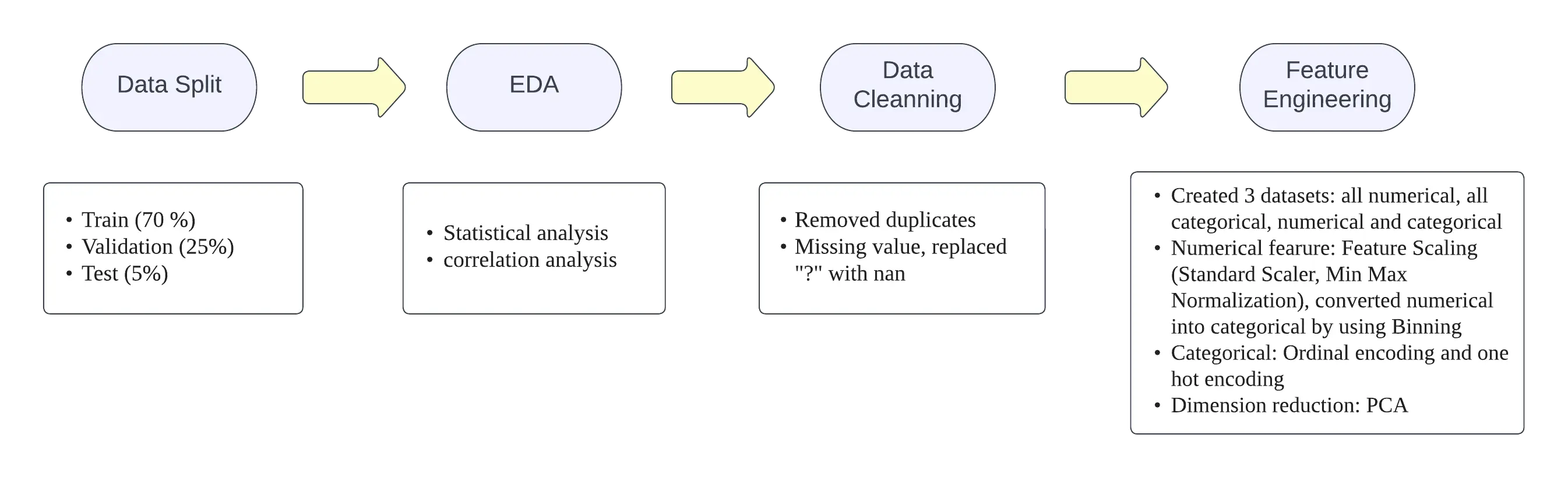
4. Exploratory Data Analysis(EDA)
Before implementing any models, we performed EDA on our training dataset. This process helps us to understand our dataset better. Statistical insights include the correlation between features, how the data is spread among the mean values, what hypothesis we can make based on the statistical information, which model would better fit, etc.
4.1. Statistical Summary of Numerical Features
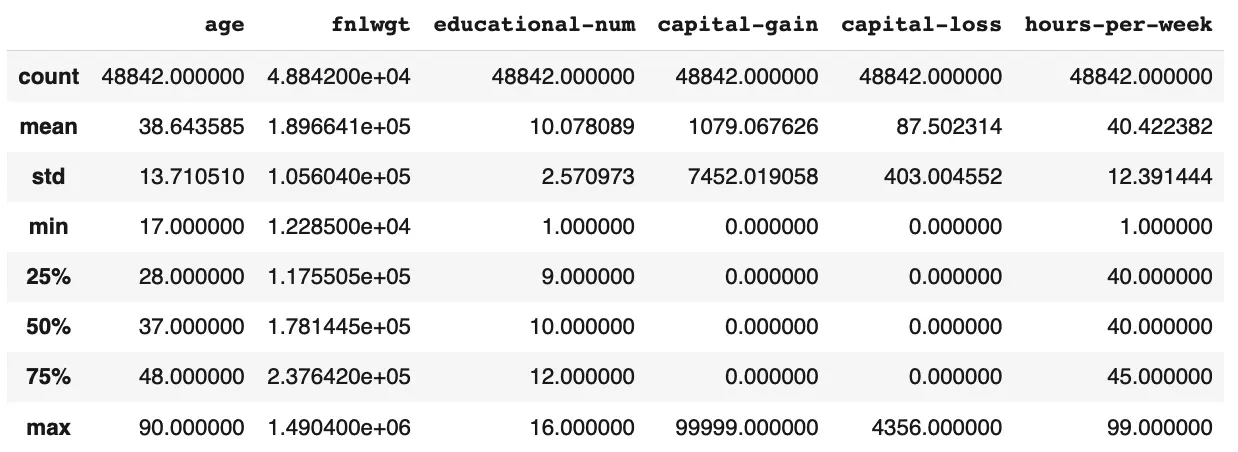
Initial Observations:
- The average age of the working classes is 38.
- The average year of education is 10 years.
- 90% of the people did not have capital gain or loss in the early 90s.
- The average of hours worked per week is 40.
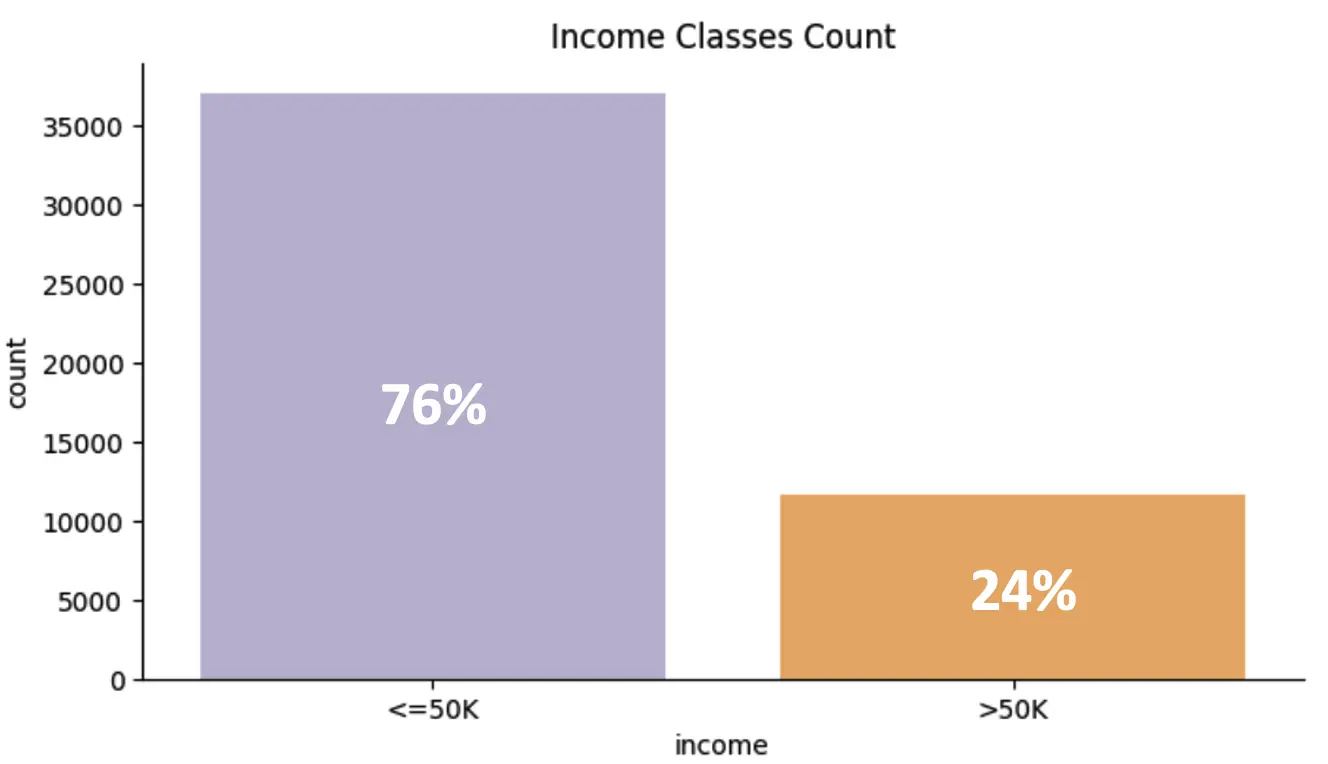
4.2. Target Class
4.3. Multivariate Analysis
Capital lossandcapital gain: most instances in these columns contained zero values in these two features. We cannot simply drop these columns, presence or no presence can be important indicators of gain or loss. So, for these sparse features, we need to deal with them based on which model we applied, that is we can keep the column as numerical values or convert it to categorical nature to show the presence or absence of gain or loss. Also, these two features are skewed such that people with high capital gain tended to have higher than 50k income.
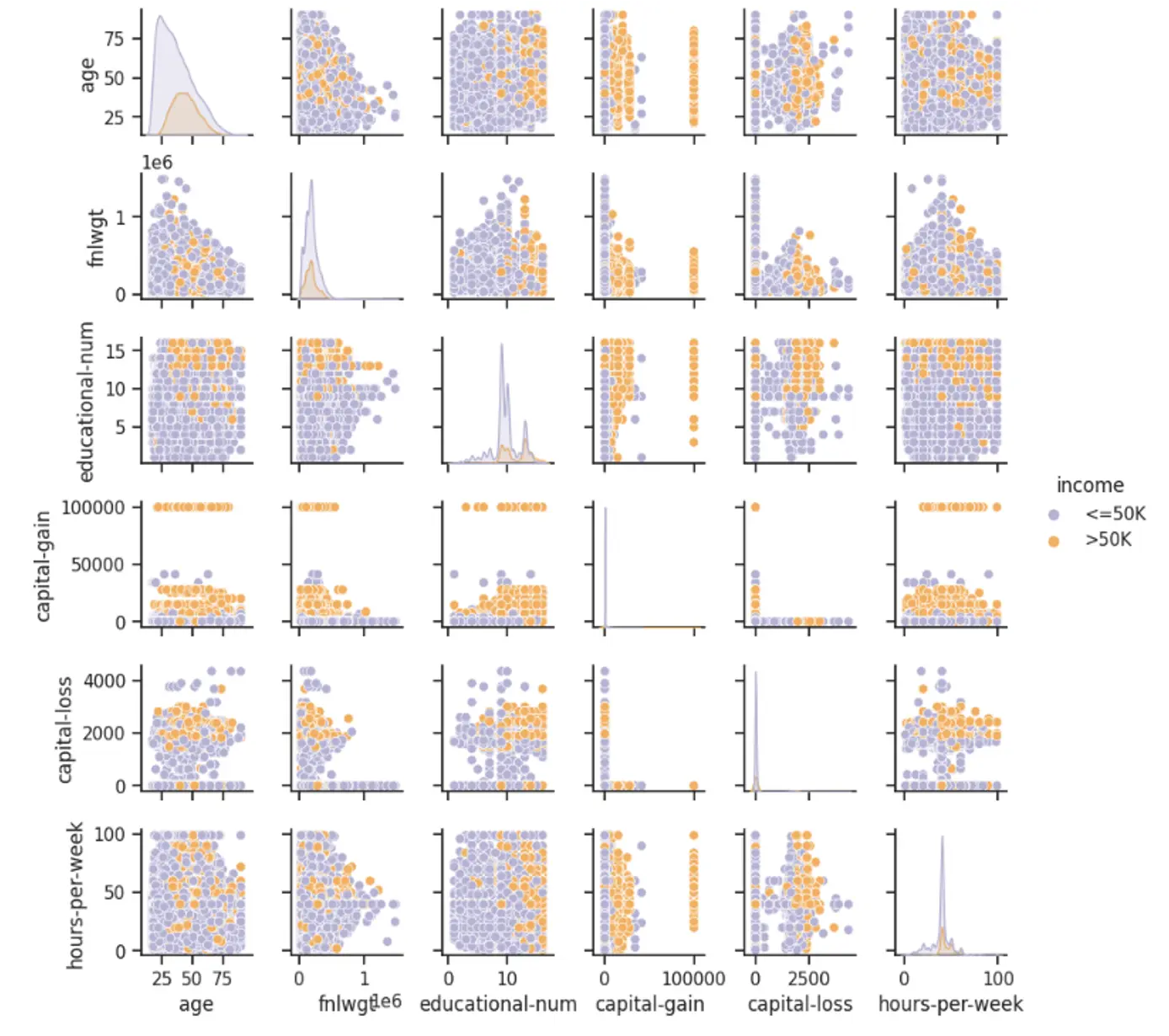
Years of Education: Those people who earn more than 50k tend to have higher education, and the variance in this high-income group is low. However, the variance of years of education has a large variance for those who earn less than 50k.Hours per week: it is the same for hours per week, the higher income group’s hours per week is around 40 hours and varied less, but for those who earn less than 50k, it looks like they are working longer.Agevs.Hours per week, as is shown in the plot, there is no clear cluster or split between classes, which shows the data is complex. Based on the information, Neural Networks and Tree-based techniques would have better performance.
5. Data Cleaning
During EDA, our goal was to understand the distribution of data in various columns and understand why null values or missing values occur.
- The Numerical columns did not contain any missing values. Two columns capital-gain and capital-loss contained high skew of zero values. These columns can be used as numerical columns or one-hot-encoded to show zero or non-zero values. The signal from these columns could be important indicators for the income classification.
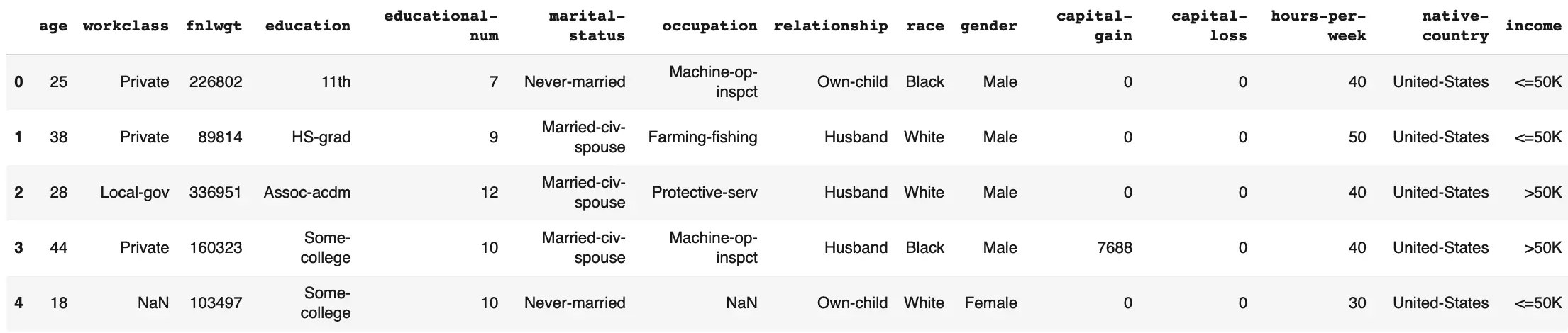
- The Categorical columns contained NAs and ”?”. All missing values, NAs, and “?” were studied and no clear pattern was found. All missing values, NAs, and “?” were converted to NULL values. For example,
workclassandoccupationin row 4 are “NULL”. Multiple approaches can be done here such as Imputing the missing values with the most common values in column etc. But in this project, these missing values are considered as a separate category.
Also from the EDA, we learnt that educational num and education category columns can be mapped one to one. So, one column can be dropped.
There were 48 duplicate rows in the 48K rows. These rows can be dropped as they do not provide additional information for classification.
6. Feature Engineering
The training dataset contained numerical and categorical columns. We performed data transformation on the original dataset and converted the data into three formats: all numerical, all categorical, and mixed categorical and numerical.
The Techniques we have used are One-hot-encoding and Ordinal-encoding for converting categorical data into numerical data; we also used standardization and Min-max normalization on all numerical data. The goal of the project was to assess:
- Impact of binning: Converting numerical columns like
Ageinto Age bin categories. The model would be input with all numerical columns fit transformed and converted to categories and categorical columns as categories themselves. The same binning transformation would be applied to validation and test datasets. - Impact of scaling: Numerical columns were evaluated for Standard Scaling and Min Max Scaling. It is important to understand how the model performs when numerical columns are transformed in either way. Also, need to check the outlier handling in the transformed dataset.
- Ordinal Encoding: Categorical columns cannot be input directly into models. All categories are encoded into ordinal categories. Ordinal categories can be also used to show the order of categories.
Overall, three datasets were created:
- Categorical dataset: Contained numerical columns binned into categories and kept all categorical columns.
- Numerical dataset: Contained all numerical columns and categorical columns encoded to 0 and 1 for each column category if the category was not ordinal. A column like
educationwas dropped as theeducation numbercolumn could be used. - Mixed dataset: Contained both numerical and categorical columns in their raw form
All these techniques will generate different performances based on models, and this will give us more options for choosing the best fit.
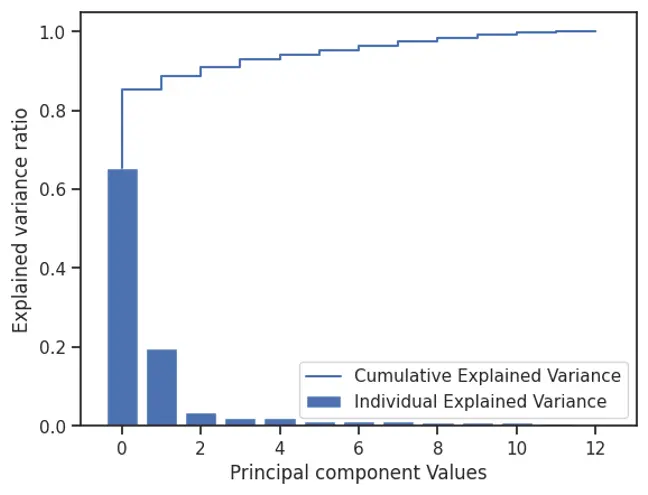
6.1 Principal Component Analysis(PCA)
We observed from EDA that there is complexity in the dataset, data is not linearly related and there are complex non-linear relationships in the dataset. So, we decided to also evaluate the impact of applying PCA on the dataset and converting the data into a lower dimensional principal component with the most information. Next, by implementing PCA, we found that the first two components contain over 90% of the information in this dataset. However, the limitation of this method is that we do not know which feature is important to us. We may be able to get model performance close to best-performing model performances with very few Principal components, but we lose explainability. So, we will be using the PCA version of the dataset only to compare with the performance of models without PCA.
7. Statistical Learning Algorithms
Model implementation: We used sk-learn’s ideal performance as a benchmark and compared it to the performance of our own models. For some cases, we also used sk-learn’s model hyperparameters to fine-tune our own models. We are evaluating the performance of each algorithm using Precision, Recall, F1-score, AUC, and Accuracy.
For our dataset, we applied the above pre-processing techniques as described in previous sections. We made sure that no data frame is manipulated when using different models. This way we ensured no change take place after the initial pre-processing. We can evaluate the impact of each technique by the performance of the algorithms. For example, we can determine whether standardization or normalization improves the performance of a particular algorithm, or whether PCA reduces the dimensionality of the data while maintaining its predictive power.
7.1. Naive Bayes
For Naive Bayes, we assume that all features are independent of each other, and numerical feature follows a Gaussian distribution.
Discrete feature: $P( 𝑦 | X_1,…,X_𝑛) \propto\ 𝑙𝑖𝑘𝑒𝑙𝑖h𝑜𝑜𝑑 * 𝑝𝑟𝑖𝑜𝑟 = P(X_i | y = k) * P(y = k)$
Continuous feature: $P(𝑋 | y = k) \sim N(\mu_{ki} , \sigma_{ki}^2), f(x) = \frac{1}{\sqrt{2 \pi \sigma_{ki}^2}} * e^{-\frac{1}{2} (\frac{𝑥_𝑖 − μ_{𝑖𝑗}}{\sigma_{ki}})^2}$
| Model Type | Data Structure | AUC | Accuracy | F1-Score | Recall | Precision |
|---|---|---|---|---|---|---|
| sk-learn | Mixed Features | 0.68 | 0.81 | 0.70 | 0.42 | 0.66 |
| sk-learn | Categorical | 0.80 | 0.81 | 0.77 | 0.77 | 0.58 |
| sk-learn | Standard Scaler | 0.64 | 0.81 | 0.66 | 0.31 | 0.70 |
| sk-learn | Min Max Scaler | 0.64 | 0.81 | 0.66 | 0.31 | 0.70 |
| sk-learn | PCA | 0.62 | 0.78 | 0.64 | 0.32 | 0.58 |
| Numpy | Categorical | 0.79 | 0.72 | 0.70 | 0.91 | 0.46 |
| Numpy | Mixed Features | 0.70 | 0.83 | 0.73 | 0.45 | 0.73 |
| Numpy | Categorical | 0.79 | 0.72 | 0.70 | 0.91 | 0.46 |
| Numpy | Standard Scaler | 0.64 | 0.81 | 0.66 | 0.31 | 0.70 |
| Numpy | Min Max Scaler | 0.62 | 0.78 | 0.64 | 0.32 | 0.58 |
| Numpy | PCA | 0.62 | 0.78 | 0.64 | 0.32 | 0.58 |
- Our best-performing model for the Naive Bayes algorithm is the one implemented by using Numpy with all categorical features, which achieved an AUC of 0.79.
7.2. Logistic Regression
The Logistic Regression model was implemented using an sk-learn model and our code on Standard Scalar, Min-Max Scalar, and PCA datasets.
\[cost(h_\theta (x), y) = \left\{ \begin{array}\\ - log(h_\theta(x)) & \mbox{if } \ y = 1 \\ - log(1 - h_\theta(x)) & \mbox{if } \ y = 0 \\ \end{array} \right.\] \[P(y|\theta, x) = (\frac{1}{1 + e^-\theta^Tx})^y*(1-\frac{1}{1 + e^-\theta^Tx})^{1-y}\]For logistic regression, we want to understand the relative importance of each feature in determining the class label. To understand that, we used SHapley Additive exPlanations(SHAPE) values, which provide a way to assign a numerical importance score to each feature.
| Model Type | Data Structure | AUC | Accuracy | F1-score | Recall | Precision |
|---|---|---|---|---|---|---|
| sk-learn | Standard Scaler | 0.70 | 0.83 | 0.73 | 0.45 | 0.74 |
| sk-learn | Min Max Scaler | 0.69 | 0.82 | 0.71 | 0.44 | 0.68 |
| sk-learn | PCA | 0.70 | 0.83 | 0.73 | 0.45 | 0.74 |
| Numpy | Standard Scaler | 0.66 | 0.77 | 0.67 | 0.46 | 0.52 |
| Numpy | Min Max Scaler | 0.52 | 0.74 | 0.51 | 0.12 | 0.34 |
| Numpy | PCA | 0.77 | 0.74 | 0.70 | 0.82 | 0.47 |
- The best model is all numerical features with standard scaling using Numpy implemented model with an AUC of 0.77.
- We applied Gradient Descent for cost minimization.
7.2.1. Feature Importance (Implementation of SHAP)
The SHAP values are calculated by randomly perturbing a single feature in the validation set and measuring the effect on the model’s prediction. This process is repeated multiple times to obtain a stable estimate of the SHAP values for each feature.
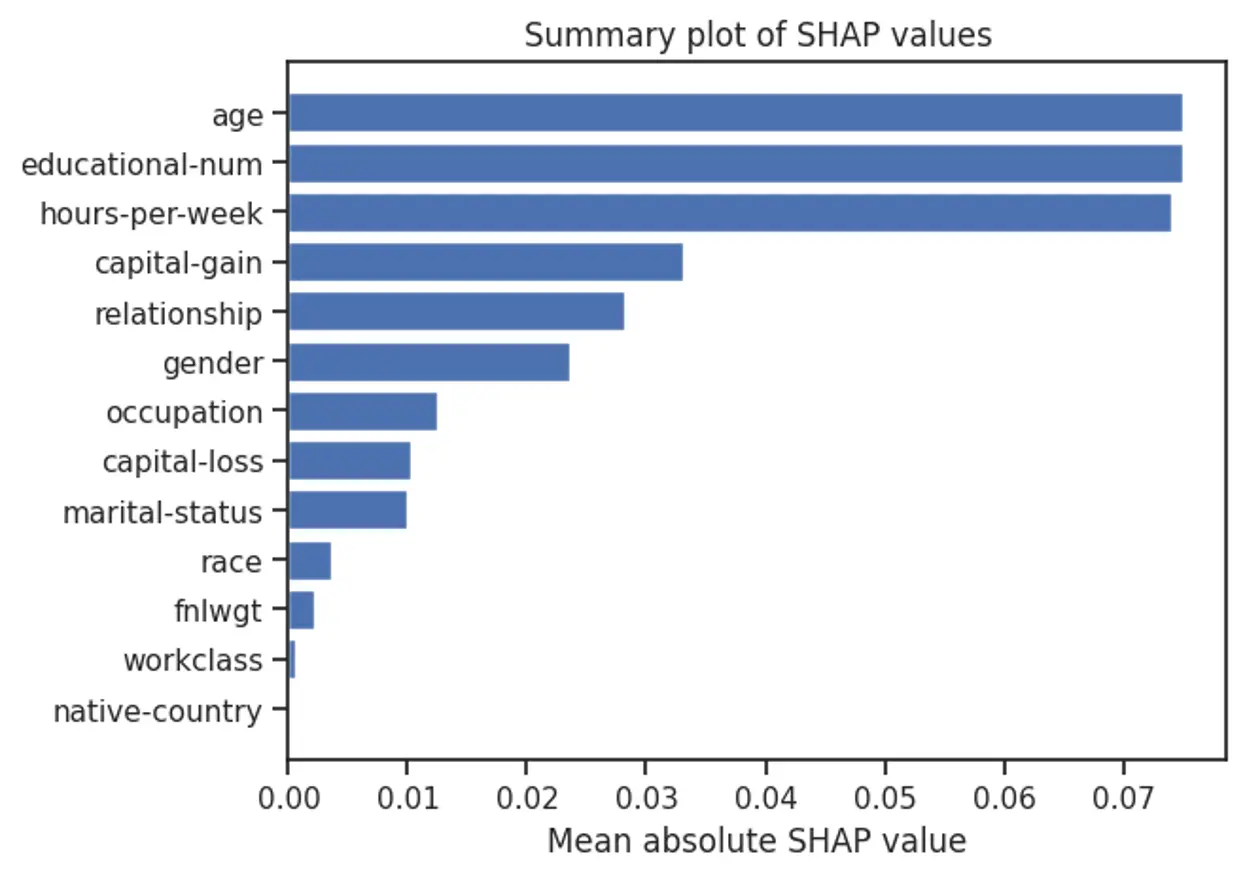
- SHapley Additive exPlanations is the showcase contribution of a feature to the prediction probability of income that is greater than $50k.
- As we can see,
Age,Education level, andhours per weekare essential in estimating the prediction probability of target classes.
7.3. Support Vector Machine (SVM)
The goal of SVM is to find a hyperplane that maximally separates data points into different classes. With 14 features, it can be difficult to visualize the results, but our goal is to find class separation between income groups on the 14 features.
For our project, we implemented a hard margin SVM model by defining various functions and performing hyperparameter tuning.
\[\textrm{Min}_{w, b} \ \ \frac{1}{2}||w||_2^2\] \[s.t. (w.x_j + b).y_j ≥ 1, \text{for} \space j = 1, ..., n\]The Adult Income dataset is complex and non-linear, which means that a Hard SVM linear model may not perform well.
| Model Name | Model Type | Data Structure | AUC | Accuracy | F1-score | Recall | Precision |
|---|---|---|---|---|---|---|---|
| Linear | sk-learn | Standard Scaler | 0.64 | 0.82 | 0.66 | 0.29 | 0.82 |
| Linear | sk-learn | Min Max Scaler | 0.63 | 0.82 | 0.66 | 0.28 | 0.84 |
| Linear | sk-learn | PCA | 0.64 | 0.82 | 0.66 | 0.29 | 0.82 |
| Soft-Margin | sk-learn | Standard Scaler | 0.62 | 0.81 | 0.64 | 0.26 | 0.86 |
| Soft-Margin | sk-learn | Min Max Scaler | 0.50 | 0.76 | 0.43 | 0.00 | 0.00 |
| Soft-Margin | sk-learn | PCA | 0.73 | 0.85 | 0.76 | 0.50 | 0.77 |
| Hard Margin | Numpy | Standard Scaler | 0.65 | 0.82 | 0.15 | 0.31 | 0.83 |
| Hard Margin | Numpy | Min Max Scaler | 0.73 | 0.85 | 0.76 | 0.50 | 0.77 |
| Hard Margin | Numpy | PCA | 0.77 | 0.75 | 0.20 | 0.82 | 0.48 |
- RBF Kernel is used for the Soft-Margin SVM models.
For the Support Vector Machine model, we got the best performance for the model we implemented on the standard scalar dataset after hyperparameter tuning, which has an AUC of 0.77.
7.4. K- Nearest Neighbours (KNN)
The KNN algorithm is a non-parametric algorithm that classifies new data points based on their proximity to existing data points in the training dataset.
\[dist_{x, y} = \sqrt{\sum_{i=1}^k(x_i-y_i)^2}\]The KNN algorithm works by calculating the distance between the new data point and the k-nearest neighbors in the training set. The majority class among the k-nearest neighbors is then assigned to the new data point. For our case, we used k = 2.
| Model Type | Data Structure | Accuracy | F1-score | Recall | Precision |
|---|---|---|---|---|---|
| sk-learn | Categorical | 0.82 | 0.6 | 0.56 | 0.65 |
| sk-learn | Standard Scaler | 0.83 | 0.62 | 0.57 | 0.67 |
| sk-learn | Min Max Scaler | 0.82 | 0.6 | 0.55 | 0.66 |
| sk-learn | PCA | 0.83 | 0.63 | 0.57 | 0.67 |
| Numpy | Categorical | 0.6 | 0.37 | 0.5 | 0.3 |
| Numpy | Standard Scaler | 0.61 | 0.37 | 0.5 | 0.3 |
| Numpy | Min Max Scaler | 0.5 | 0.31 | 0.48 | 0.23 |
| Numpy | PCA | 0.5 | 0.31 | 0.48 | 0.23 |
Overall, KNN does not have a good performance based on the comparison between our benchmark and group-implemented model on different datasets.
7.5. Decision Tree
The methodology of the decision trees involves recursive partitioning of the data based on the values of the input feature to create a tree-like model that can be used for classifications. It is commonly applied when the data is complex, meaning no clear separation between classes. For our project, we used cross entropy to validate the purity of classification.
We applied the decision trees on our dataset under 4 scenarios, first where all data were categorical, next, we evaluated it on standardized numerical data, normalized numerical data, and lastly on numerical data with PCA.
\[P_i = \frac{\text{ # income above 50k} \text { or } \text{income below 50k}}{\text{# Sub-nodes}}\] \[Entropy = \sum_{i= 1}^n -P(C_i)log_2(P(C_i)) \\\] \[\text{where} \space p(C_i)\space \text{is the probability of class} \space C_i \space \text{in node i}\]Entropy denotes the uncertainty of the data, it measures the impurity in a node. When a node contains various classes, it will have a higher entropy than a node that has only one class (PURE). Entropy has a range from 0 to 1.
7.5.1. Decision Tree
| Model Type | Data Structure | AUC | Accuracy | F1-score | Recall | Precision |
|---|---|---|---|---|---|---|
| sk-learn | Categorical | 0.72 | 0.81 | 0.73 | 0.54 | 0.61 |
| sk-learn | Standard Scaler | 0.75 | 0.82 | 0.75 | 0.63 | 0.61 |
| sk-learn | Min Max Scaler | 0.75 | 0.82 | 0.75 | 0.63 | 0.61 |
| sk-learn | PCA | 0.73 | 0.80 | 0.73 | 0.59 | 0.57 |
| Numpy | Categorical | 0.72 | 0.83 | 0.74 | 0.50 | 0.72 |
| Numpy | Standard Scaler | 0.77 | 0.81 | 0.76 | 0.69 | 0.61 |
| Numpy | Min Max Scaler | 0.71 | 0.83 | 0.73 | 0.46 | 0.76 |
| Numpy | PCA | 0.69 | 0.82 | 0.71 | 0.44 | 0.64 |
7.5.2. Random Forest
| Model Type | Data Structure | AUC | Accuracy | F1-score | Recall | Precision |
|---|---|---|---|---|---|---|
| sk-learn | Standard Scaler | 0.76 | 0.85 | 0.78 | 0.58 | 0.74 |
| sk-learn | Min Max Scaler | 0.76 | 0.85 | 0.78 | 0.58 | 0.74 |
| sk-learn | PCA | 0.74 | 0.84 | 0.76 | 0.55 | 0.71 |
For the Decision tree, the model implemented on all numerical Standard scalar data performed the best, with AUC 0.77, and accuracy 0.88
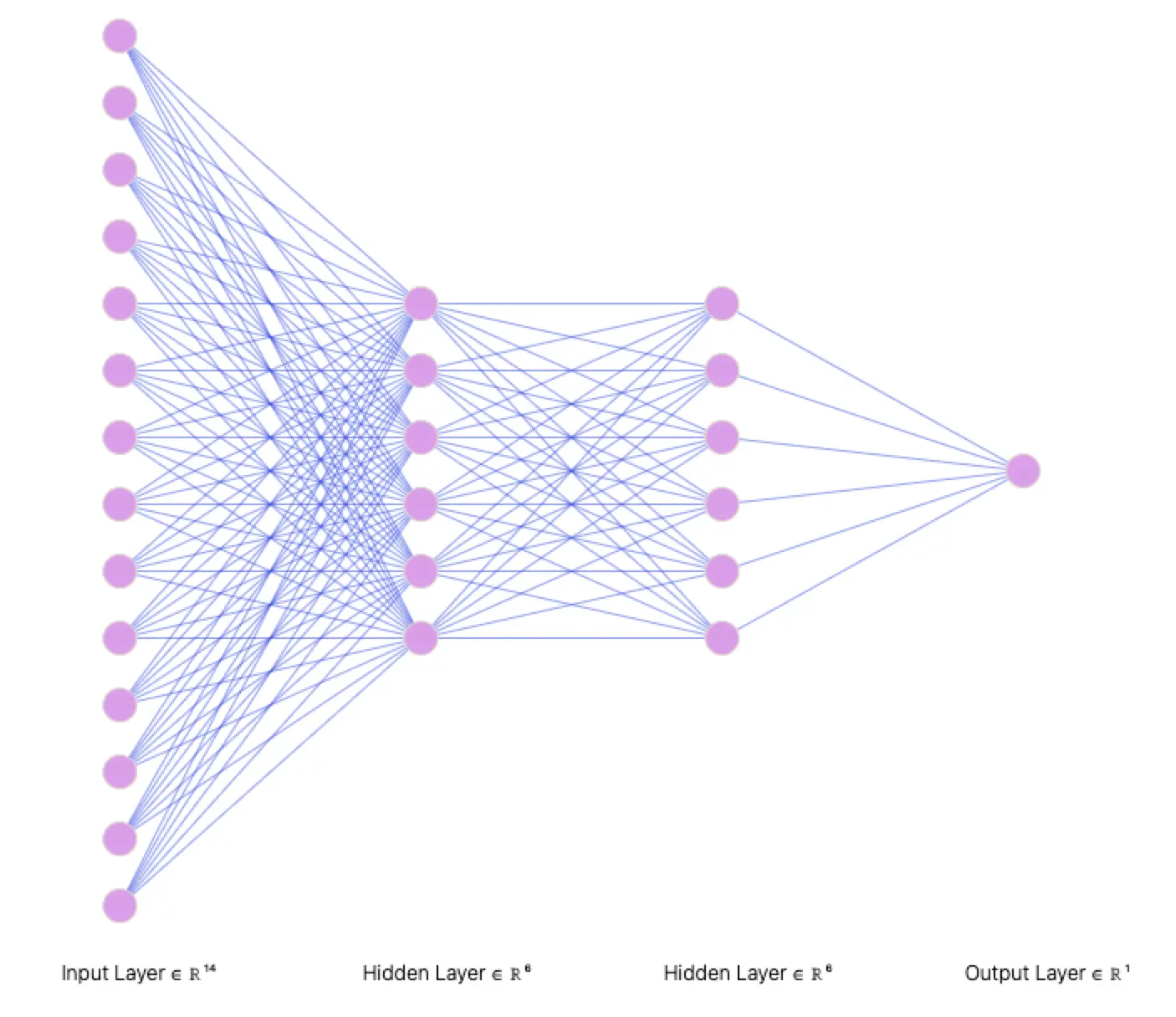
7.6. Neural Network
For the Adult Income dataset classification, our neural network model consists of an input layer with 14 neurons, two hidden layers, and an output layer. The ReLU activation function was used for the hidden layer to introduce non-linearity, and the sigmoid activation function was used for the output layer to predict the binary output.
| Neural Network Architecture | Activation Function |
|---|---|
 |
 |
Results:
| Data Structure | AUC | Accuracy | F1-score | Recall | Precision |
|---|---|---|---|---|---|
| Standard Scaler | 0.77 | 0.85 | 0.78 | 0.62 | 0.70 |
| Min Max Scaler | 0.76 | 0.85 | 0.78 | 0.59 | 0.72 |
| PCA | 0.75 | 0.85 | 0.77 | 0.57 | 0.73 |
The best-performing model is the one with Standard Scaled numerical features, One-hot-encoded Categorical columns fed into the Neural Network with 2 Hidden layers with 6 nodes each with ReLU activation and a final Output layer with Sigmoid activation. It achieved a Precision of 0.78.
8. Results and Comparison
To evaluate the best performance models, we applied the Receiver Operating Characteristic(ROC) curve (ROC), which plots True Positive Rate(TPR) v.s. False Positive Rate (FPR) at different classification thresholds, and we are using 0.5 as the threshold. AUC(Area under the Curve) measures the area underneath the entire ROC curve.
Overall, the Neural Network and Decision Tree show the best performance and the highest AUC score of 0.79 is achieved by the Discrete Naive Bayes model (all categorical features).
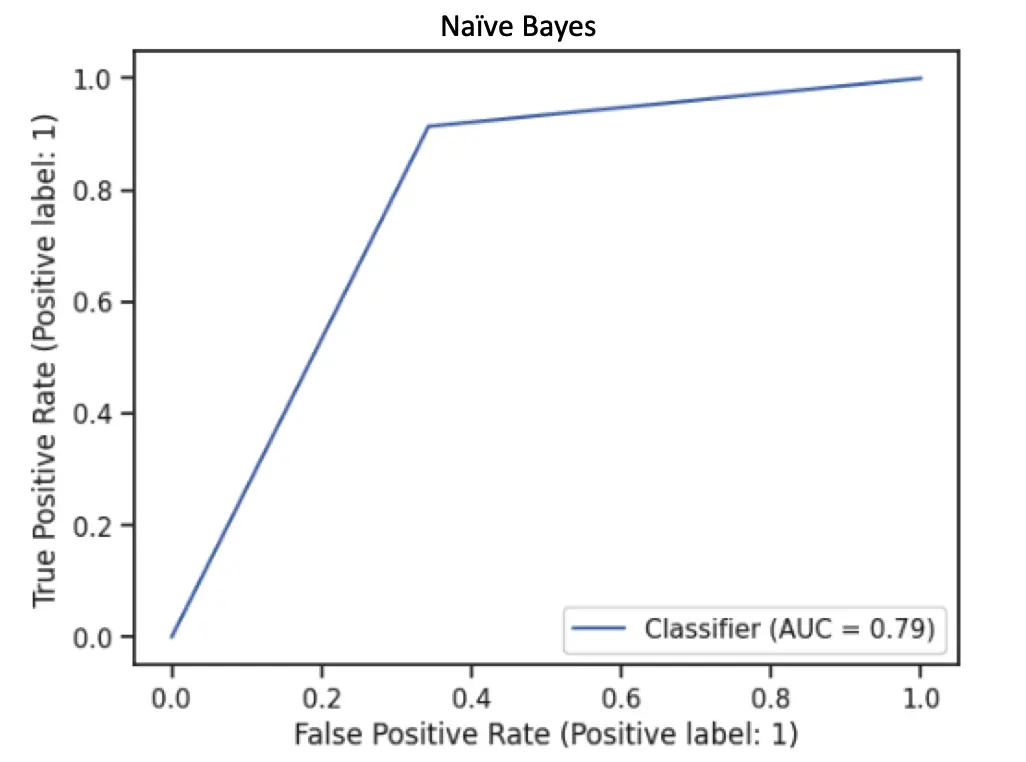
As we know, a good fit model is not just to achieve high AUC, we have to consider the computation costs, time complexity, etc. Therefore, we have measured the time complexity versus AUC for all group-implemented models. There is a trade-off between time and average AUC for Neural Networks; this model has a higher AUC but also takes a long time to run because of the complex computation.
| Decision Tree | Neural Network |
|---|---|
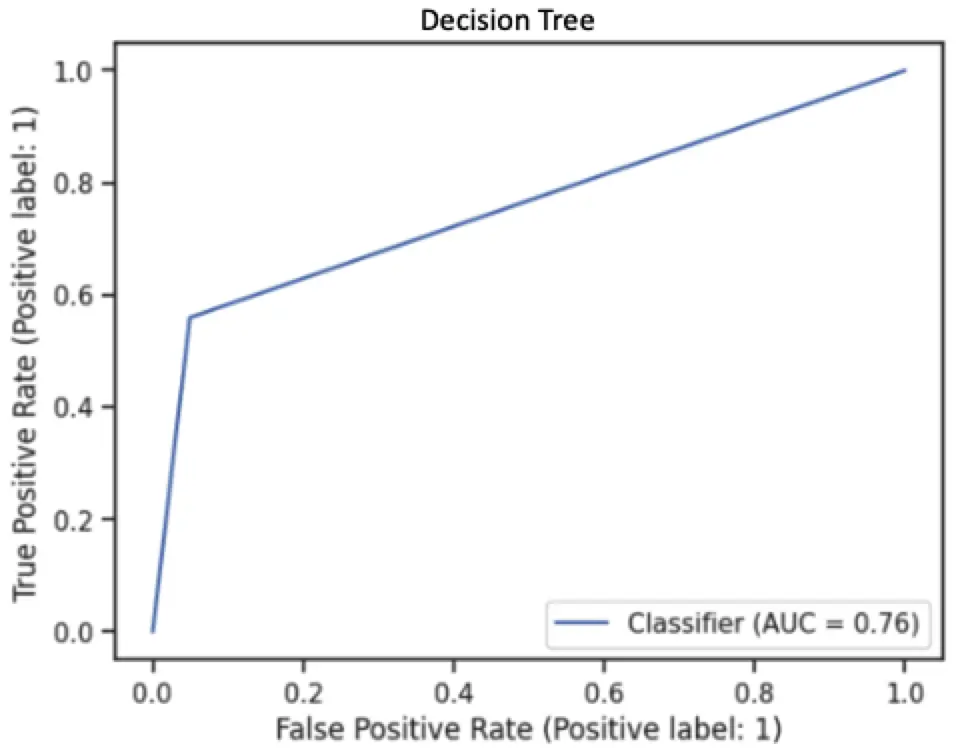 |
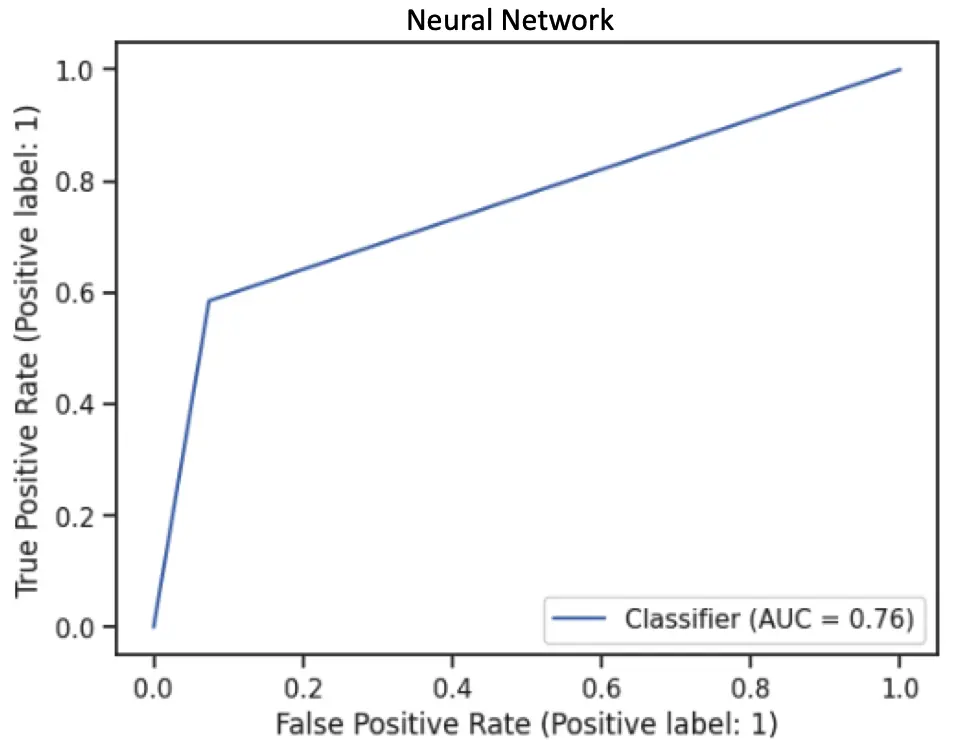 |
As we compare the ROC curve for Naive Bayes with Neural Network and Decision Tree, we can see Naive Bayes has a larger area under the curve, which represents a higher AUC score. On the other hand, Decision Tree and Neural Network predicted more True positive classes at the 0.5 thresholds.
Best Performing model
After training all models on the training dataset and evaluating the validation dataset. We find that the Neural Network model performed the best with Standard Scaled numerical columns. We then compared the validation dataset performance metrics with the test dataset performance metrics. We found that the Neural network performances are close. That is we don’t see overfitting or underfitting. So, the Neural Network model with Standard Scaled columns can be used used for future predictions.
| Metrics | Model Name | AUC | Accuracy | F1-Score | Recall | Precision |
|---|---|---|---|---|---|---|
| Validation | Neural Network | 0.744 | 0.849 | 0.768 | 0.544 | 0.748 |
| Test | Neural Network | 0.738 | 0.848 | 0.761 | 0.536 | 0.725 |
Time complexity
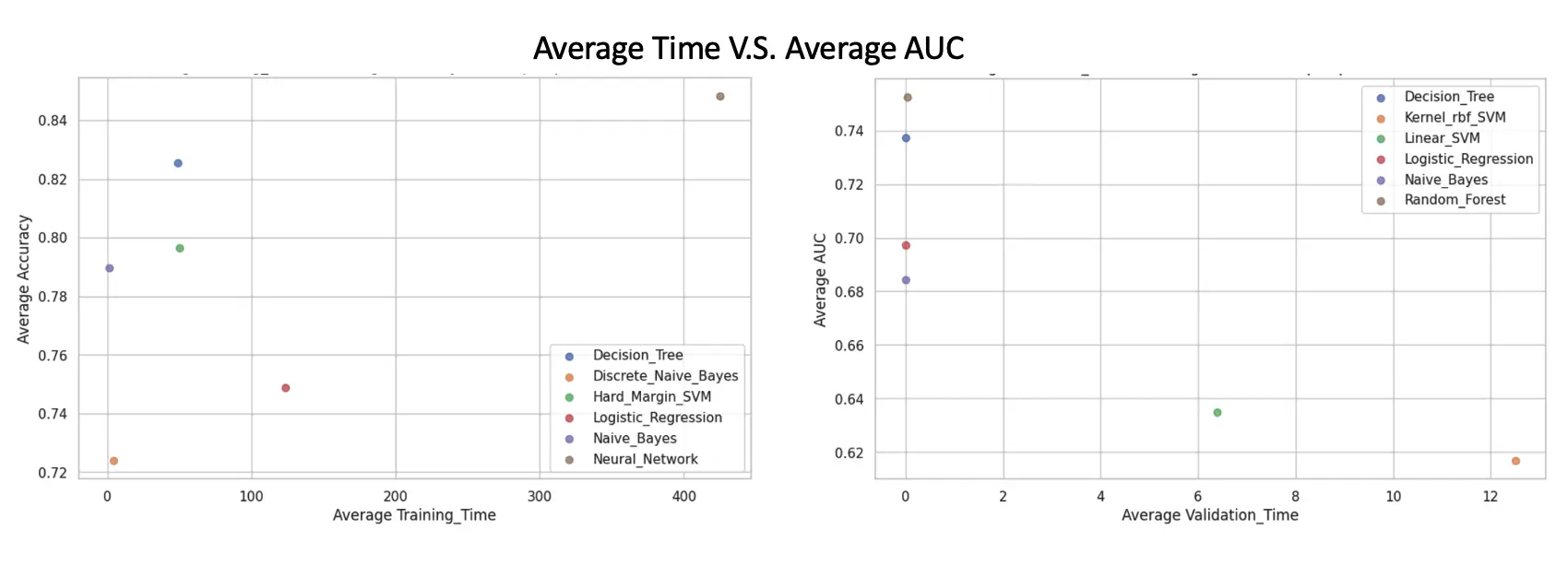
We computed Training and Validation time with respect to the average model performance of AUC for Scikit-learn benchmark models and Numpy implemented models.
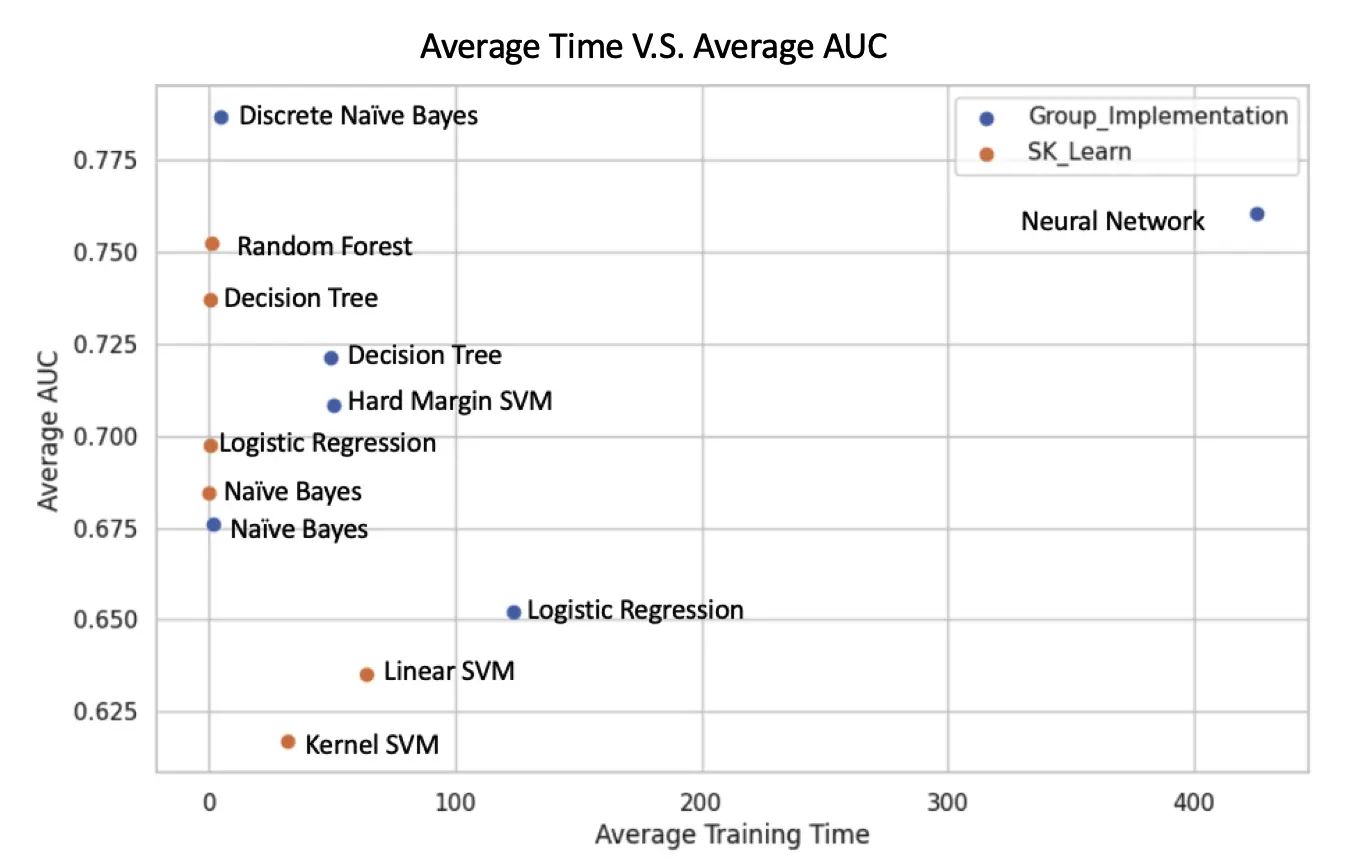
We can see how training vs validation training time changes with respect to each of the models implemented. Neural networks take the most training time but are the most accurate, validation time is minimal too.
9. Bias and Variance Trade-off
In machine learning, there is no perfect model. No matter which model we apply, there will be sacrifices and trade-offs, which is why feature engineering is important. The goal for prediction is not only the minimum error and the model can learn from the data and correctly apply it to other datasets.
\[E_{x, y, D}[(h_D(x)-y)^2] = E_{x, D}[(h_D(x)- h'(x))^2] + E_{x, y}[(y'(x)-y)^2] + E_{x}[(h'(x)- y'(x))^2]\] \[\text{Expected test error} = \text{Variance}\ \ + \ \text{Noise} \ \ + \ \ \text{Bias}^2\]When the model has a high bias, it tends to underfit the data as the model is forced to reach the minimum error. The variance is how much variability is in the target function in response to a change in the training data. A high variance means the model tends to overfit the data.
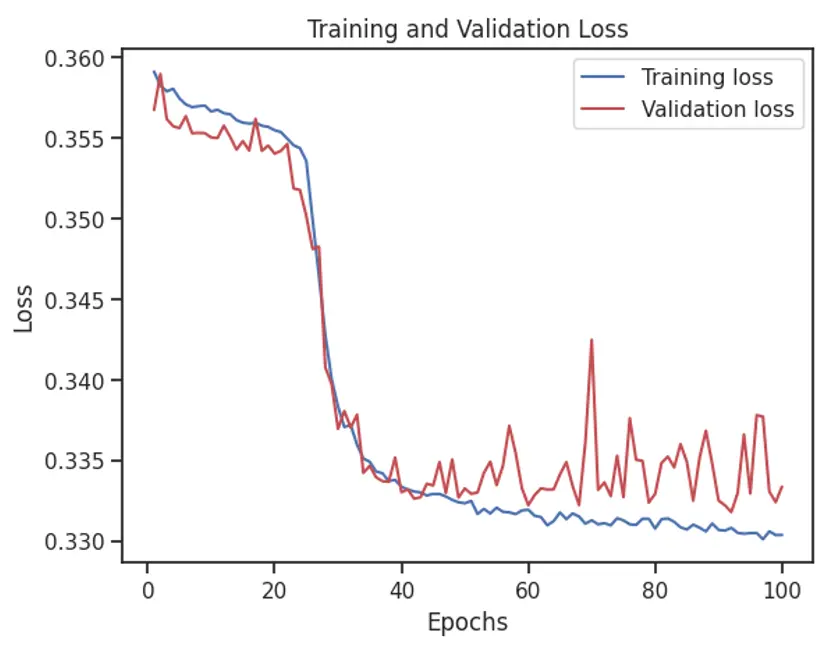
This is the learning progress from Neural Network. After 40 epochs, the model started to overfit the validation data as high variance occurred.
In our model implementation, we have plotted the loss from train data and validation data to evaluate the fit and minimized the error.
10. Summary
- Exploratory Data Analysis: No clear feature separation or cluster between classes, but we see people with higher education levels tend to have greater than $50k income.
- Feature Importance: Logistic Regression + SHAP Value estimation allows us to explain and understand why age, education, hours per week worked, and capital gain strongly impacted classification.
- Feature Scaling: Based on the various data pre-processing methods we saw performance differences between columns with Min Max Scaling and Standard Scaler. The standardized dataset achieved better results with most models.
- Principal Component Analysis: PCA helped consolidate information carried by features into 2-3 columns with the highest variance, but we lose out on explainability crucial to our model use case. We did not see too much significance with the dataset with PCA.
- Training vs Validation Time complexity: Models can be picked based on the various performance metrics while trading off the Training and validation time. Ex: Neural Network has a high Training time but gives high accuracy and AUC scores.
- Performance metrics: Overall best performance is shown by Neural networks and Decision Trees. Best AUC scores are achieved by Naïve Bayes with Binned Numerical columns. Bias Variance trade-off/loss curves can be used to pick models.