Outline:
In this project of clustering for customer segmentation, we will delve into the essential exploratory data analysis techniques, unsupervised learning methods such as K-means clustering, followed by Cluster Analysis to create targeted profils for customers. The goals of this project comprise data pipeline preparation, ML model training, ML model update, exploring the extent of data and concept drifts (if any), and CI/CD Process demonstration. Thus, this project shall serve as a simulation for real-world application in the latest competitive business landscape. We aim to further apply these clustering algorithms to gain insights into customer behavior, and create a recommendation system as a future scope for lasting impact on customer satisfaction and business success.
1. Dataset information
This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. The company mainly sells unique all-occasion gifts. Many customers of the company are wholesalers. The initial dataset has 541909 rows and 8 columns. The dataset can be downloaded from this UCI repository.
Below is a summary of the column information of the original retail dataset.
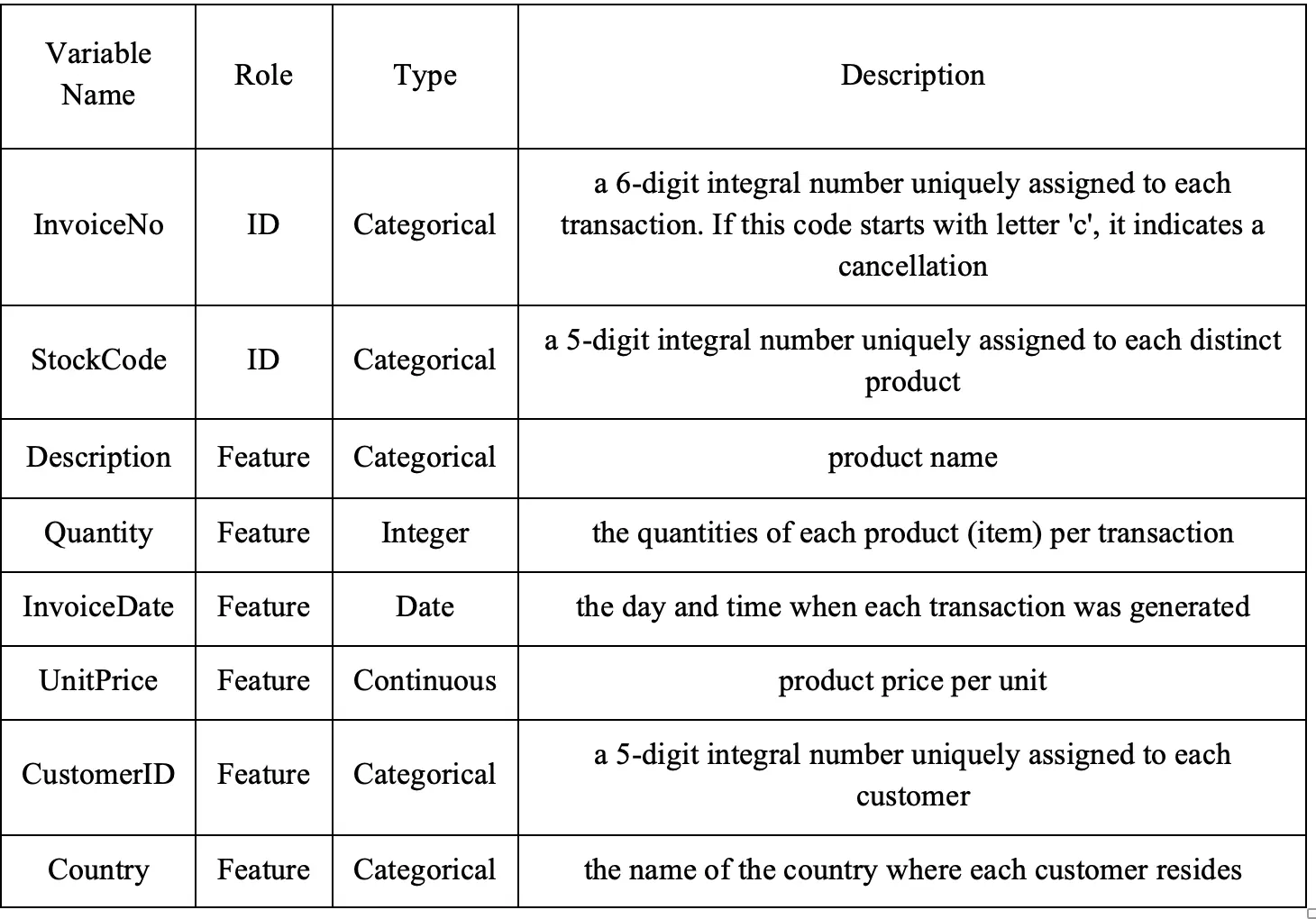
2. Data Rights and Privacy
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. This allows for the sharing and adaptation of the datasets for any purpose, provided that the appropriate credit is given.
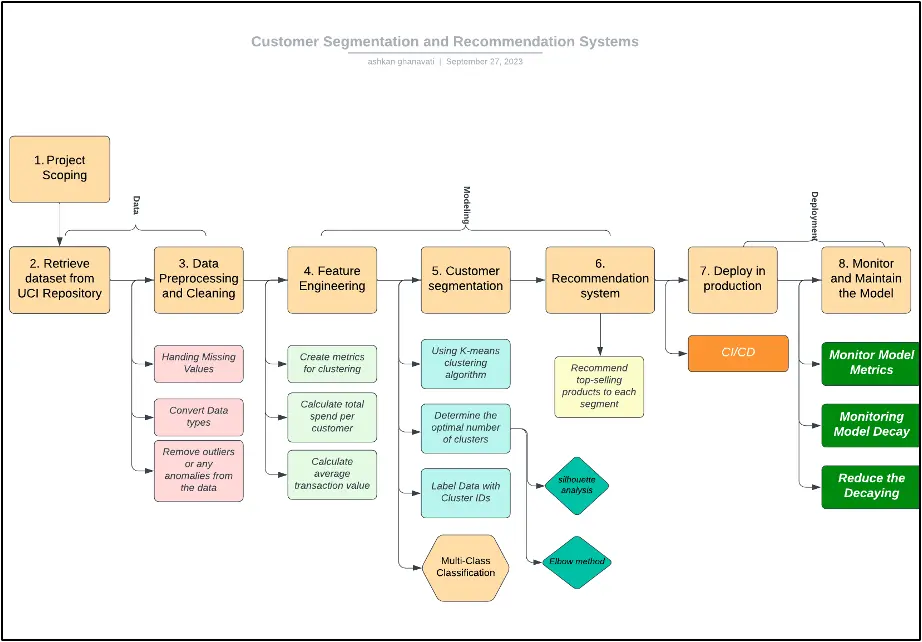
3. Current Approach Flow Chart and Bottleneck Detection
Flow of tasks for this project is depicted and laid out in a visual flow chart to help better understand the steps to accomplish the goal of this project. This flow might face multiple bottlenecks along the way which are required to be addressed in the scoping step. Potential bottlenecks are as following:
- Data preprocessing is prolonged due to excessive missing data or corrupted records.
- Delaying some steps might affect subsequent steps. For example, if determining the number of clusters is not clear-cut, it could delay the entire segmentation process.
- Kubernetes, especially, involves numerous configuration settings to ensure the desired behavior. Getting the configurations right can be time-consuming and complex.
4. Metrics, Objectives, and Business Goals
4.1 Primary Objectives
The primary objective of this project is to perform customer segmentation, which will enable us to identify distinct customer profiles and gain insight into the preferences of various customer groups. The ultimate goal is to leverage this tool as part of a marketing strategy to enhance the company’s sales.
4.2 Model Performance Metrics
To determine the most appropriate number of clusters, we will employ both the elbow and Silhouette methods. These methods are designed to identify the optimal number of clusters by minimizing the within-cluster sum-of-squares (WCSS), which is also known as inertia. After establishing the optimal number of clusters, our next step is to assess the quality of these clusters.
4.3 Business Goals
- Increase the average invoice value by at least 10% based on order value.
- Gain insights on the nature of purchase(personal buy, bulk buy, resellers) contingent on quantity purchased to provide targeted deals and promote sales.
- Find regions of high purchase activity based on location demographics and promote targeted advertising campaigns for product preferences.
- Promote relevant products based on similarity scores to increase order/invoice value.
5. Deployment Infrastructure
This project is automated by integrating cloud tools and orchestrating platforms such as Apache Airflow from the data preprocessing to monitoring steps. Below is a summary of deployment steps:
- We will use Google Cloud Platform (GCP) to deploy our machine learning model.
- Implement data ingestion processes into a data pipeline using API calls and store it on Cloud Storage.
- Using Cloud Composer (A fully managed Apache airflow service) or Cloud Dataflow (A fully managed stream and batch processing service), we orchestrate the data pipelines.
- Train and save the machine learning model(s) using a framework like TensorFlow, or scikit-learn.
- On the AI Platform, package the model code and dependencies into a container.
- Set up monitoring and logging to monitor the model’s performance.
- Version the trained models to track changes and allow easy rollbacks.
- Implement CI/CD pipelines to automate the deployment process, updating and maintaining the models.